
データの標準化とは統計学の用語で、「データ科学便覧」サイトの「統計学における標準化」ページによると、
統計学における標準化 (standardization) とは,与えられたデータを平均が0で分散が1のデータに変換する操作のことをいう.正規化とか規格化とも呼ばれる.、
とあります。標準化を行う理由としては、
元のデータの分布上より標準正規分布のような素性が明らかな分布上でデータを議論するほうが便利で簡単になるからである.
と書かれています。
ボストンデータセットの場合でいうと、説明変数に当たるcrim(犯罪発生率)やzn(広い宅地の割合)、indus(非小売業の土地面積の割合)といった12個の属性値の、たとえば1が意味する大きさが、属性によってまちまちなので、全部をまとめて扱うときには、1が意味する大きさを揃える方が話が簡単になる、ということです。
標準化は、
以下のように各データ xi から平均 μ を引き,その値を標準偏差 σ で割ることで達成される。
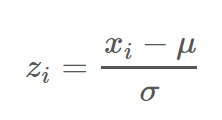
ので、これを行うには、平均と標準偏差が必要になります。
標本集団の分散および標準偏差は標本分散および標本標準偏差と呼び,それぞれ s2 および s で表される.これらの量は標本集団そのもののばらつきを知りたいときにのみ用いる.母分散および母標準偏差の不偏推定量ではない.n はデータ数,xは平均値.
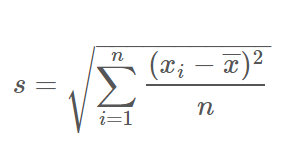
相当難解な言い回しですが、かみくだくと、標準偏差は、各データの値と、平均の差の2乗の合計を、データの総数で割った値の正の平方根で求めることができます。これを行うのがdetermineMeanAndStddev()関数です。
determineMeanAndStddev()関数の計算内容を確認してみます。ただし膨大な数値を扱っているので、関数に渡すのをcrimのデータだけにして、結果を分かりやすくします。
// crimのデータだけ取り出す。
const [trainFeaturesTF_CRIM, rest] = trainFeaturesTF.split([1, 11], 1);
//console.log(trainFeaturesTF_CRIM.dataSync())
let { dataMean, dataStd } = determineMeanAndStddev(trainFeaturesTF_CRIM);determineMeanAndStddev()関数には、次のようにconsole.log()を加えて値を出力するようにします。コード内のconsole.log()の行の右のコメントは、出力結果の抜粋です。
// 標準偏差:各データの値と、平均の差の2乗の合計を、データの総数で割った値の正の平方根
const determineMeanAndStddev = (data) => {
// 各データの値の平均
const dataMean = data.mean(0);
console.log(dataMean.dataSync()); // Float32Array [3.3603415489196777]
// 各データの値と平均との差
const diffFromMean = data.sub(dataMean);
console.log(diffFromMean.dataSync()); // Float32Array(333) [-3.3540215492248535, -3.33303165435791, ...]
// 各データの値と平均との差の2乗
const squaredDiffFromMean = diffFromMean.square();
console.log(squaredDiffFromMean.dataSync()); // Float32Array(333) [11.249460220336914, 11.109100341796875, ...]ビジュアルテキスト
// 各データの値と平均との差の2乗の平均
const variance = squaredDiffFromMean.mean(0);
console.log(variance.dataSync()); // Float32Array [53.89356994628906]
// 各データの値と平均との差の2乗の平均の平方根
const dataStd = variance.sqrt();
console.log(dataStd.dataSync()); // Float32Array [7.341224670410156]
return {
dataMean, dataStd
};
}この結果からは、crim列の数値の平均が3.3603415489196777であり(data.mean(0))、各の値とその平均との差を計算し(data.sub(dataMean))、その2乗を求め(diffFromMean.square())、その平均を出して(squaredDiffFromMean.mean(0))、平方根を計算する(variance.sqrt())という手順を進めることで、「各データの値と、平均の差の2乗の合計を、データの総数で割った値の正の平方根」という標準偏差7.341224670410156を算出していることが分かります。
下図はこれと同じことを、エクセルで行った結果のシートです。上図の出力とほぼ同様の計算結果が出ているのが分かります。
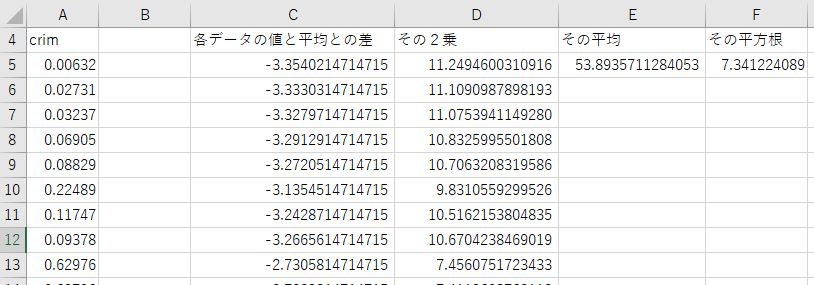
データの標準化は、そのデータから平均を引き、それを標準偏差で割ることで実行できます。これを行うのがnormalizeTensor()関数です。
const normalizeTensor = (data, dataMean, dataStd) => {
return data.sub(dataMean).div(dataStd);
}メインのJavaScriptで、normalizeTensor()関数にcrim列のデータと平均値、標準偏差を渡して、その結果を出力してみます。
const trainFeaturesNormalized_CRIM = normalizeTensor(trainFeaturesTF_CRIM, dataMean, dataStd);
console.log(trainFeaturesNormalized_CRIM.dataSync());下図は、crim列の各データが標準化された実行結果です。

これは、前のエクセルでも同様の結果を得ることができます。
