
初めに概略を述べておくと、「不思議の国のアリス」風の文章を生成するには、「4_1_1:LSTM 文章生成サンプル」で示したml5.charRNN()の第1引数を、「不思議の国のアリス」のモデルへのパスに変えるだけです。たとえばモデルがmodels/aliceというフォルダにある場合には、
charRNN = ml5.charRNN(‘./models/alice/’, modelReady);
となります。
本記事は「Training a LSTM」を日本語訳し一部修正したものです。
この短いチュートリアルは、カスタムLSTMを独自のデータセットで訓練し、そのモデルをml5.charRNN()メソッドで使用する方法を示すものです。そのためには、使用したいテキストのデータセットを用意する必要があります。
このチュートリアルのコードは、Andrej Karpathy’s char-rnn codeのSherjil Ozairバージョンをベースにしています。
目次
必要な環境
tensorflowをインストールしたPython環境。
tensorflowモデルを作成するので、Pythonコードが実行できる環境が必要になります。Python環境であるAnacondaをWindowsにインストールし、そこにTensorFlowをインストールする方法は「9_1 tensorflowjs converterを使えるようにする」で述べているので、参考にしてください。
手順
- 「ml5js/training-lstm」から訓練セットをダウンロードする。
画面右に[Clone or download]ボタンがあるので、ZIPファイルをダウンロードし展開します。するとtraining-lstm-masterフォルダが現れます。使用するのはこのフォルダです。
- データを入手する。
LSTMは、入力から文章のシーケンス(つながり)やパターンを予測したいときにうまく機能する。入力データはできるだけ多く入手する。多ければ多いほどよい。
データが準備できたら、このプロジェクトのルートに新しいフォルダを作成し、そのフォルダ内に、訓練データのテキストファイルをinput.txtという名前で配置する。
(小さなさまざまな.txtファイルを1つの大きな訓練用ファイルに連結するには、ls *.txt | xargs -L 1 cat >> input.txtコマンドが使用できる) - 訓練する。
- 使用する。
モデルの準備ができたので、そのモデルを参照するようにml5.charRNN()を変更する。charRNN = ml5.charRNN('./models/alice/', modelReady);aliceフォルダを、「ml5-examples/p5js/LSTM/LSTM_Text」サンプルのmodelsフォルダ内にコピーします。
LSTM 文章生成サンプルを開いて、[シードテキスト]にAlice askedを入力し[生成]ボタンをクリックすると、「不思議の国のアリス」風の文章が生成されます。それをGoogle翻訳にかけると、次のような結果が得られます。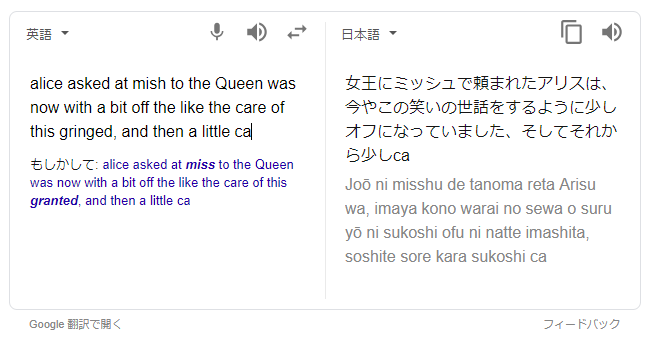
「Free ebooks – Project Gutenberg」では、数多くの文学作品がデジタルデータで公開されています。「不思議の国のアリス」の英文データは「Alice’s Adventures in Wonderland by Lewis Carroll」の「11-0.txt」から入手できます。
11-0.txtをダウンロードしたらテキストエディタで開き、ファイルの前後にある作品以外の文章を削除し、input.txtという名前に変更します。
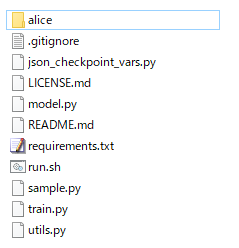
training-lstm-masterフォルダ直下にaliceという名前のフォルダを作成し、input.txtをaliceフォルダにコピーします。training-lstm-masterフォルダ内には、下図に示すフォルダやファイルが並んでいることになります。
訓練用スクリプトをデフォルト設定で実行するコマンド。
python train.py --data_dir=./folder_with_my_custom_dataまた、訓練時のハイパーパラメータを指定することもできる。
python train.py --data_dir=./folder_with_my_custom_data --rnn_size 128 --num_layers 2 --seq_length 64 --batch_size 32 --num_epochs 1000 --save_model ./models --save_checkpoints ./checkpointsこれにより、モデルが訓練され、./modelsという名前のフォルダにモデルのJavaScript版が保存される。
また、run.shという名前のスクリプトを実行する方法もある。
bash run.shこのファイルには前述したものと同じパラメータが含まれている。
# これは、訓練時に変更できるハイパーパラメータ
python train.py --data_dir=./bronte \
--rnn_size 128 \
--num_layers 2 \
--seq_length 50 \
--batch_size 50 \
--num_epochs 50 \
--save_checkpoints ./checkpoints \
--save_model ./models
tensorflowをインストールしたPython環境(Anaconda Prompt)を起動し、training-lstm-masterフォルダに移動します。具体的に言うと、Anaconda Promptにcdコマンドを入力し、そこにtraining-lstm-masterフォルダをドロップしてEnterキーを押します。
次のコマンドを入力し実行します。訓練には相応の時間がかかるので、訓練の繰り返し回数を意味するnum_epochsの数を、初めは小さくしておくのが賢明です。python train.py --data_dir=./alice --rnn_size 128 --num_layers 2 --seq_length 64 --batch_size 32 --num_epochs 50 --save_model ./models --save_checkpoints ./checkpointstrain.pyを実行すると、モデルが作成され、そこに文章のデータが与えられて訓練が始まります。
train_lossの値は言ってみれば、正解とモデルの推測値のギャップで、これが小さいほどモデルの精度が高まったことになります。上記コードではepochに50を指定しているので、訓練は比較的速く終わります。
Model saved to ./checkpoints\alice\alice!
Converting model to ml5js: alice alice-3599
Done! The output model is in ./modelsと表示されたら、訓練の終了です。training-lstm-masterフォルダにmodelsフォルダが作成され、その中にaliceフォルダが作成されています。aliceフォルダの中にあるのが、「不思議の国のアリス」のJavaScript版モデル本体です。
ハイパーパラメータ
訓練用データセットのサイズについて、以下に参考になるハイパーパラメータの値を示す。
2 MB
- rnn_size 256 (または128)
- layers 2
- seq_length 64
- batch_size 32
- dropout 0.25
5-8 MB
- rnn_size 512
- layers 2 (または3)
- seq_length 128
- batch_size 64
- dropout 0.25
10-20 MB
- rnn_size 1024
- layers 2 (または3)
- seq_length 128 (または256)
- batch_size 128
- dropout 0.25
25 MB以上
- rnn_size 2048
- layers 2 (または3)
- seq_length 256 (または128)
- batch_size 128
- dropout 0.25