
MNISTの訓練用とテスト用の画像データとラベルデータを表すtf.Tensorオブジェクト4つが作成できたので、次はモデルの構築と訓練です。
手書き数字の認識にどんなモデルが適しているのか、考えてもしかたないので、TensorFlow.jsのmnistサンプルで使用されているものをそのまま流用することにします。
このモデルはCNN(畳み込みニューラルネットワーク)の方法をとったモデルで、CNNは画像データの分類に用いられる筆頭の方法です。下図のようなレイヤー構造を作成します。
この方法でなぜ、手書き数字が認識できるようになるのかについては、「How do Convolutional Neural Networks work?」を日本語に翻訳した「畳み込みニューラルネットワークの仕組み」などを参考にしてください。
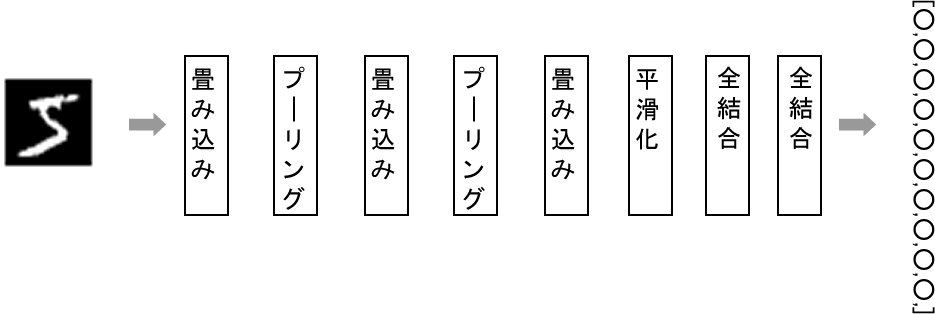
モデルは次のコードで作成します。なお、TensorFlow.jsのmnistサンプルに記述されている英文コメントの日本語訳も加えているので、参考にしてみてください。
// TensorFlow.jsのサンプルに使用されているモデル
// https://github.com/tensorflow/tfjs-examples/tree/master/mnist
const buildModel = () => {
// シーケンシャルなニューラルネットワークモデル。
// tf.sequential()関数は、レイヤーの出力が次のレイヤーの入力となる
// 層を重ねたモデルを作成するAPIを提供する。
//
const model = tf.sequential();
// 1つめのこのレイヤーには、ニューラルネットワークの入力レイヤーであるとともに、
// 入力に対し最初の畳み込み演算を行うという2つの役割がある。
// このレイヤーは28 x 28のモノクロ画像を受け取り、。
// それぞれ3ピクセルのカーネルサイズを持つフィルターを16個使用する。
// また、ちょうどこんな感じ__/の、単純なRELU活性化関数を使用する。
model.add(tf.layers.conv2d({
inputShape: [28, 28, 1],
kernelSize: 3,
filters: 16,
activation: 'relu'
}));
// 2つめはMaxPoolingレイヤー。これは、領域の平均ではなく最大値を用いた
// ダウンサンプリングのようなことを実行する。
model.add(tf.layers.maxPooling2d({
poolSize: 2,
strides: 2
}));
// 3つめは再度畳み込みレイヤーで、今度は32個のフィルターを持っている。
model.add(tf.layers.conv2d({
kernelSize: 3,
filters: 32,
activation: 'relu'
}));
// MaxPoolingレイヤーをもう1つ。
model.add(tf.layers.maxPooling2d({
poolSize: 2,
strides: 2
}));
// 畳み込みレイヤーをさらにもう1つ
model.add(tf.layers.conv2d({
kernelSize: 3,
filters: 32,
activation: 'relu'
}));
// このレイヤーでは、最後のレイヤーの入力とするために、2Dフィルターの出力を1Dベクトルに平滑化する。
// これは、より高い次元のデータを最終の分類出力レイヤーに与えるときに、よく用いられる手法。、
model.add(tf.layers.flatten({}));
model.add(tf.layers.dense({
units: 64,
activation: 'relu'
}));
// 最後のレイヤーは、それぞれがクラス(つまり0, 1, 2, 3, 4, 5, 6, 7, 8, 9)を出力する
// ユニットを10個持つ Denseレイヤー。
// ここでは実際にクラスが数値を表すが、たとえばクラスが犬と猫のようなほかの実体を表すような場合でも同じ。
// このレイヤーでは、10クラスにわたる確率分布を生み出し、合計が1になるように、
// 出力の活性化関数としてソフトマックス関数を使用している。
model.add(tf.layers.dense({
units: 10,
activation: 'softmax'
}));
// オプティマイザー(最適化アルゴリズム)の定義
// オプティマイザーは、モデルの訓練中、訓練の損失を減らし、分類の精度が上がるように、
// モデルの重み値を最適化する。
// 学習率は、訓練の各ステップ(繰り返し)で重みの更新に使用する大きさを定義する。
// この値が大きいほど、損失値は速く収束するが、それは同時に、更新を行うときに最適なパラメータを飛び越えてしまう可能性もある、
// ということを意味する。低すぎる学習率は最適な(または十分に良い)重みパラメータの検出に時間がかかり、
// 高すぎる学習率は最適なパラメータを飛び越えてしまう可能性がある。
// 学習率は、適切に設定すべき、最重要なハイパーパラメータの1つ。
// 適切な値を見つけるには練習が必要で、通常は多くの値を試すことで最適な値が見つかるものだ。
const learningRate = 0.01;
// 使用するオプティマイザーはrmsprop。オプティマイザーは、双方向的な方法で損失関数を最小化し、
// モデルの重みパラメータに関する損失関数の最小値を見つけようとする。
const optimizer = 'rmsprop';
// モデルは、オプティマイザーと損失関数、モデルの評価に使用する評価関数のリストを指定することで、コンパイルする。
// ここでは、MNISTの数当てのようなクラスが複数ある分類問題によく選ばれるカテゴリカルクロスエントロピー損失関数を使用する。
// カテゴリカルクロスエントロピー損失関数は可微分なのでモデルの訓練にも使用できる。
// しかし人間による解釈は容易ではないので、サンプル多さが分類の精度となる'metric'、つまり精度を指定している。
// この評価関数は可微分でないので、モデルの損失関数には使用できない。
model.compile({
optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}モデルを作成したら、訓練に移ります。以下はモデルを作成し、訓練するコードです。これも、mnistサンプルを参考にしています。
model = buildModel();
model.summary();
const train = async() => {
console.log('モデルの訓練開始');
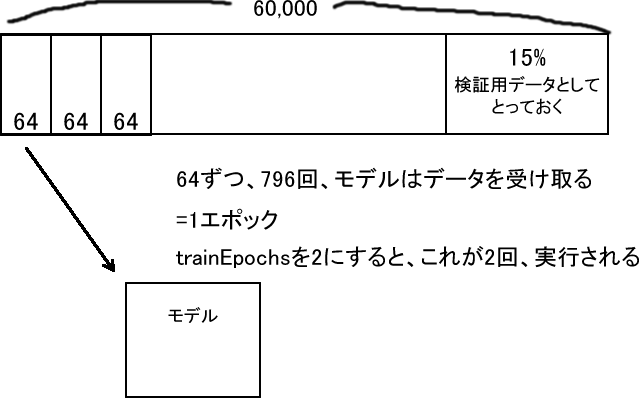
// バッチサイズも重要なハイパーパラメータの1つで、訓練中、モデルの重みを更新するときに与えるひとまとめのサンプル数、
// つまりバッチを定義する。値が低すぎると少ないサンプルで重みを更新するので、うまく一般化できない。
// バッチサイズが大きいとそれだけ大きなメモリリソースが必要になるので、良好なパフォーマンスが約束されない。
//
const batchSize = 64;
// 訓練時の過学習の監視のため、訓練用データの最後15%を検証用に残す。
const validationSplit = 0.15;
// 訓練全体の繰り返し回数
const trainEpochs = 1;
// 訓練全体を通してのバッチ処理回数を保持する変数
let trainBatchCount = 0;
// 合計のバッチ数 = 60000 * (0.85 / 64) * 1 = 796
const totalNumBatches = Math.ceil(trainXS.shape[0] * (1 - validationSplit) / batchSize) * trainEpochs;
// 長い時間のかかる、モデルを訓練するfit()の呼び出し中にコールバックを設定しているので、
// 訓練の進捗に合わせて、ページに損失値と精度値をプロットできる。
let valAcc;
await model.fit(trainXS, trainYS, {
batchSize,
validationSplit,
epochs: trainEpochs,
callbacks: {
// 1バッチ処理後に呼び出される
// batchSize=64の場合には、64サンプルを処理した後呼び出される。
// 今の場合なら、796回(51,000/64)呼び出される
onBatchEnd: async(batch, logs) => {
trainBatchCount++;
console.log('batch :' + batch)
showInfoBatch(`訓練中... (` + `${(trainBatchCount / totalNumBatches * 100).toFixed(1)}%` + ` 完了)`);
plot(trainBatchCount, logs.loss, trainBatchCount, logs.acc);
// TensorFlow.js内部でwindow.requestAnimationFrame()を呼び出す
await tf.nextFrame();
},
// 1エポック処理後に呼び出される
// epochsが1なら1回、3なら3回呼び出される
onEpochEnd: async(epoch, logs) => {
console.log('epoch :' + epoch);
valAcc = logs.val_acc;
showInfoEpoch(epoch + 1 + '回めのエポック終了時点での検証用データに対する損失値: ' + logs.val_loss + ', 正確度: ' + logs.val_acc + '<br/>');
await tf.nextFrame();
}
}
});
// 訓練が終わったモデルの正確度を、テストデータを与えて調べる
const testResult = model.evaluate(testXS, testYS);
// テスト用データに対する正確度
const testAccPercent = testResult[1].dataSync()[0] * 100;
// 検証用データに対する正確度
const finalValAccPercent = valAcc * 100;
showInfoFinal(
`検証用データに対する正確度: ${finalValAccPercent.toFixed(1)}%; ` +
`テスト用データに対する正確度: ${testAccPercent.toFixed(1)}%`);
trainXS.dispose();
trainYS.dispose();
testXS.dispose();
testYS.dispose();
}
await train();モデルのfit()に与えているいくつかの変数には、次の意味があります。詳しくはコードのコメントを参照してください。
ここまでを実行すると、下図のような結果を得ることができます。
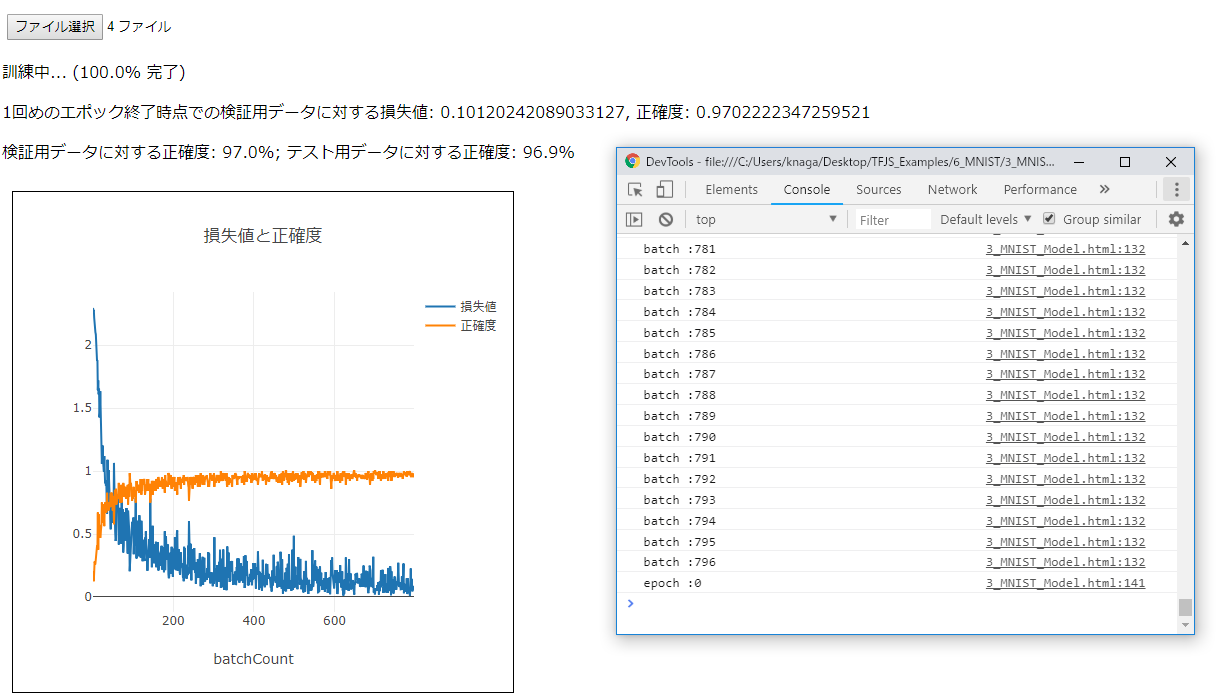
この例ではtrainEpochsに1を指定しているので、データを64ずつ796回与える訓練は1回しか実行されません。trainEpochsに2や3を指定すると、正確度はさらにアップし、訓練に要する時間も長くかかります。