
何はなくともデータを準備する必要があります。今回使用するのは、次のようなデータです。前述したように、分かりやすくするために、サンプル数を少なくしています。
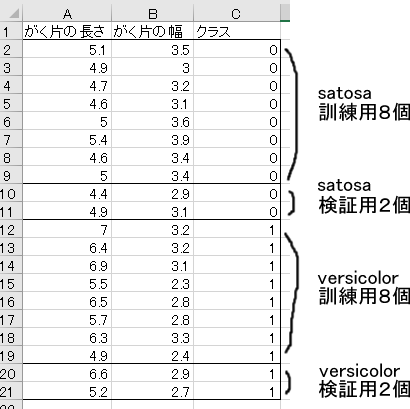
JavaScriptコードでは、訓練用のデータを8個ずつ配列に入れて、Plotlyで分布図を描いています。
// satosaデータの1個めから8個めまでの、
// がく片の長さと幅を選び出したもの(2特徴量)
const satosaData = [
[5.1, 3.5],
[4.9, 3.0],
[4.7, 3.2],
[4.6, 3.1],
[5.0, 3.6],
[5.4, 3.9],
[4.6, 3.4],
[5.0, 3.4]
];
// versicolorデータの1個めから8個めまでの、
// がく片の長さと幅を選び出したもの(2特徴量)
const versicolorData = [
[7.0, 3.2],
[6.4, 3.2],
[6.9, 3.1],
[5.5, 2.3],
[6.5, 2.8],
[5.7, 2.8],
[6.3, 3.3],
[4.9, 2.4]
];訓練用の配列は、この2つを足すとできあがります。
// 訓練用データ
// がく片の長さと幅の2特徴量
const trainXData = satosaData.concat(versicolorData);教師用の配列は、手作業で作成しています。
// 教師用データ
const trainYData = [
// satosa
[1,0], [1,0], [1,0], [1,0], [1,0], [1,0], [1,0], [1,0],
// versicolor
[0,1], [0,1], [0,1], [0,1], [0,1], [0,1], [0,1], [0,1]
];[1,0]はsatosaに、[o, 1]はversicolorに対応しています。モデルは、 [5.1, 3.5]や[4.9, 3.0]、[4.7, 3.2]が[1,0]で、[7.0, 3.2]や[6.4, 3.2]、[6.9, 3.1]が[0, 1]だという関係性を探っていきます。
検証用のデータも手作業で作成しています。
// 検証用データ
const validationXData = [
// satosaデータの9個めから10個めまでを選び出したもの
[4.4, 2.9],
[4.9, 3.1],
// versicolorデータの9個めから10個めまでを選び出したもの
[6.6, 2.9],
[5.2, 2.7]
];
const validationYData = [
// satosaデータ
[1, 0],
[1, 0],
// versicolor
[0, 1],
[0, 1]
];そして、データの配列を一度にtf.Tensorオブジェクトに変換する関数を定義して、それをstart()関数内で呼び出し、tf.Tensorオブジェクトのデータとして取得しています。
// 訓練と検証用のデータをtf.Tensorオブジェクトに変換し配列に入れて返す
const getData = async() => {
const xsTrain = tf.tensor2d(trainXData, [16, 2]);
const ysTrain = tf.tensor2d(trainYData, [16, 2]);
const xsValidation = tf.tensor2d(validationXData, [4, 2]);
const ysValidation = tf.tensor2d(validationYData, [4, 2]);
return [xsTrain, ysTrain, xsValidation, ysValidation]
}// ページが読み込まれたら、モデルの訓練まで進む
const start = async() => {
const [xsTrain, ysTrain, xsTest, ysTest] = await getData();
const model = await buildModel();
train(model, xsTrain, ysTrain, xsTest, ysTest);
}
start();これでデータが取得できたので、モデルを作成し、データをモデルに渡して訓練に移ります。