
「boston-housing」では、ボストンデータセットと呼ばれる、ボストン市郊外における地域別の住宅価格のデータセットが使われています。このデータは、Googleのデータ保存サイトからそれぞれ、train-data.csv、train-target.csv、test-data.csv、test-target.csvという名前のCSVファイルとして入手できます。
下図の左はtrain-data.csvを、右はtrain-target.csvをエクセルで開いたところです。シートの行は両方とも334あります。1行めには「crim」、「zn」といった住宅価格に関係していそうな属性名が入っているので、各属性のデータ数は333です。
train-target.csvには「medv」という属性が1つだけ含まれています。これは住宅価格です。
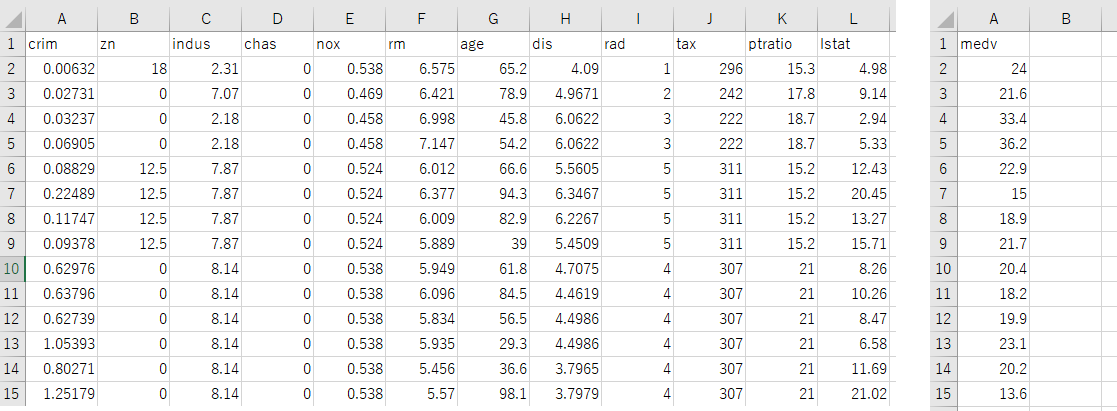
train-data.csvの2行め以降と、train-target.csvの2行め以降は対応しています。つまり、train-data.csvの2行めにある各属性の数値によってtrain-target.csvの2行めにある住宅価格になり、3行めにある各属性の数値によってtrain-target.csvの3行めにある住宅価格になっている、という関係性が成立しています。train-data.csvのデータは説明変数として、train-target.csvのデータは目的変数として、モデルの訓練に使用します。
test-data.csvとtest-target.csvの構造と関係性も同様で、データは173個含まれています。train-data.csvとtest-data.csvの1行めに書かれている属性は全部で12あり、以下の意味を持っています。
- crim 犯罪発生率
- zn 広い宅地の割合
- indus 非小売業の土地面積の割合
- chas 川に近いかどうか
- nox 窒素酸化物の濃度
- rm 平均部屋数
- age 古い家の割合
- dis 通勤距離
- rad 幹線道路へのアクセス
- tax 所得税率
- ptratio 1教室当たりの生徒数
- lstat 学校中退率
容易に想像できるのは、たとえばrm(平均部屋数)が大きい値の地域の住宅価格は高いだろうとか、dis(通勤距離)が小さい値の地域も住宅価格は高いだろうとかいう関係性(これは単回帰分析)ですが、そこにたとえばcrim(犯罪発生率)やnox(窒素酸化物の濃度)などが絡んでくると話は複雑になるだろうということも、容易に想像できます。
この問題に対し、よくできたモデルを作成しうまく学習させると、複雑な要因が絡み合う住宅価格を、そのモデルが予測できるようになる、というわけです。