
強化学習とは、「ディープラーニングを使用した強化学習とその可能性」(PDFファイル)に、次のように説明されています。
試行錯誤を通じて、「最終的な報酬を最大化するような行動」を学習することを言う。
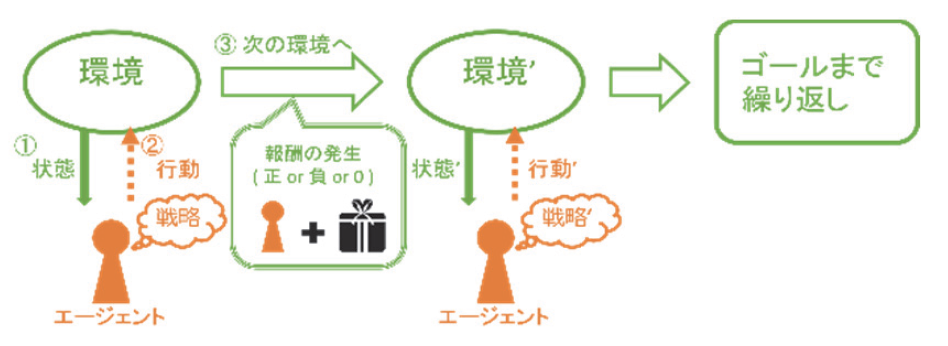
さらに同ファイルには、下図とともに、次のように記述されています。
強化学習における一連のプロセスは以下のようにモデル化する。
状態(Status):環境が今どうなっているかを表す。
行動(Action):エージェント(学習対象)が環境に対して、どのような行動を起こせるかを表す。
報酬(Reward):ある状態において、エージェントが行動を起こした結果、発生する値。
戦略(Policy):報酬を最大にする行動を選択する関数
これを、カートポールサンプルの場合で平たく言うと、ふらつく不安定なポール(状態)に対し、カートを右か左のどちらに移動させるかを選ぶことができます(行動)。そのとき、ポールが倒れずまたカートが外に出なければ、よくやったという褒美(報酬)が与えられ、ポールが倒れたりカートが外で出てしまったら、褒美は与えられません。TensorFlow.jsのモデルは、この情報を各ステップごとに与えられ、報酬が最大になる戦略(どれだけ長く、ポールを倒さずに、範囲内にいつづけられるか)を学習します。
ここまでの、簡単な説明でも分かるように、強化学習のハードルは相当高い(つまり理解がかなり大変)です。